Яндекс Вордстат – это сервис компании Яндекс, используемый для подбора ключевых слов путем анализа поисковых запросов пользователей.
В основном он применяется для составления семантического ядра. Wordstat бесплатен, он является многофункциональным инструментом, но настолько простым, что разобраться сможет даже новичок. С помощью Вордстата возможно узнать подробную статистику запросов в системе Яндекс за последний месяц, и составить не только структуру целого сайта, но и отдельных его страниц. В практике сервис применяется для решения следующих проблем:
Это самое основное, но есть конечно и более мелкие задачи, которые помогает решить Wordstat.
Сначала там нужно зарегистрироваться. Вот ссылка на сервис , вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
Также важно, чтобы в вашем профиле в Яндексе был указан ваш регион, по которому вы и собираетесь смотреть статистику запроса. Иначе, если вы будете искать, сколько клиентов для вашего бизнеса вводят в ваших Нижних Васюках слово «удочки», а у вас стоит регион Москва, то вам может выдать, что сотни тысяч людей ищут удочки. Вы накупите их сотню тысяч, а в Нижних Васюках их ищут всего-то пара калек.
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:

Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
В основном с Вордстатом работают через специальные сервисы и программы. Тысячи их! Самая известная — Кей Коллектор. Все эти программы повышают удобство работы с этим инструментом в разы.
Напрямую с вордстатом работают очень редко, однако я слышал офигенные истории, что в студии Ашманова, одной из самых крутых SEO-студий, сидят мартышки, которые каждый запрос вводят в Вордстат руками и копируют выдачу в.txt-файл. Я сразу представил сотню рабов, которые за день работы выполняют такой же объем, как один сеошник с Кей Коллектором.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1
— переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.
В блоке 2
— очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.
В блоке 3
— дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.
В блоке 4
— выбираем регион/регионы.
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:

А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:

В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:

Но самое профессиональное начинается, когда вы работаете с операторами.
Надо знать, как пользоваться операторами Яндекс Вордстата, чтобы наиболее эффективно работать в интерфейсе.
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».

С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
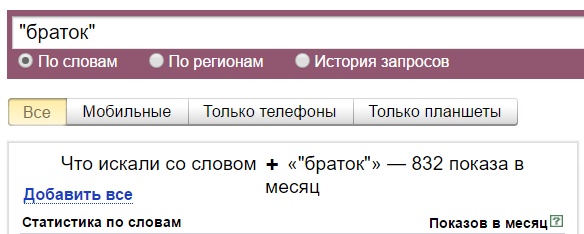
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.

А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
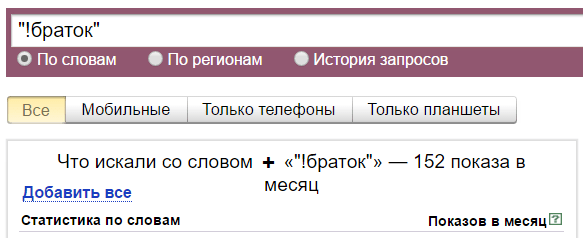
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
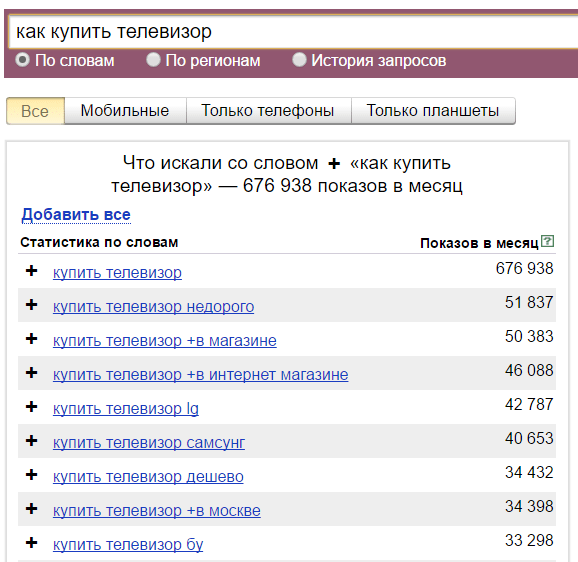
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:

Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
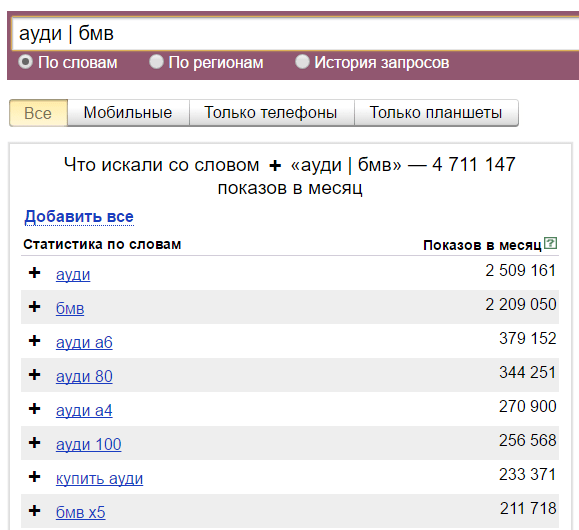
Он кстати позволяет провести сравнение двух запросов, для этого я его в основном и использую.
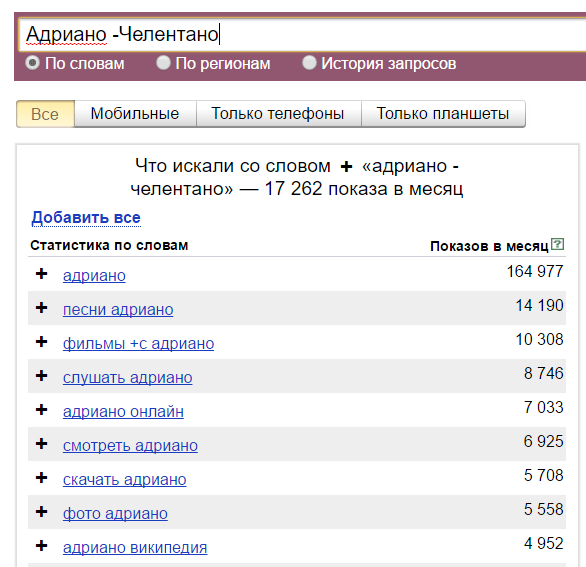
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
Круглые скобки «()» — группирует использование нескольких операторов.

Квадратные скобки «» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:

Как видим, с неправильным порядком фразу почти никто не вводит:

Работать с голым Яндекс Wordstat в целом неудобно. Чтобы облегчить свой труд, можно установить себе в браузер специальный плагин, предназначенный для работы в Wordstat. Плагины для браузеров Хромиума (Яндекса, Мейла, Амиго, Оперы и Гугл Хрома) одинаковые, а вот для Мозилы идет отдельный плагин, все являются бесплатными и доступными для скачивания, устанавливать их можно сразу из браузера. Наиболее популярные — плагины Wordstat Assistant и Yandex Wordstat Helper.
Пожалуй, самый лучший плагин для wordstat.yandex.ru. Я сам им пользуюсь. Он удобен в использовании, практичен и не мешает, когда вы работаете на других сайтах. Установленный wordstat assistant запускается только в случае перехода на страницу Вордстата. Путем нажатия на плюсики, требуемое ключевое слово можно добавить в список (он находится слева). В ассистант есть возможность отсортировать выбранные ключевики, а ненужные удалить. Получившийся список просто скопируйте в буфер обмена, и перенесите в Excel для последующей обработки. Кстати, удобность использования плагина еще и в том, что когда вы добавляете в список уже находящиеся там фразы, дубли автоматически удаляются, что существенно сокращает работу.
Этот плагин попроще, чем предыдущий, но не менее популярен, его также можно устанавливать прямо с браузера. Хелпер сделан в виде виджета, который добавляется на страницу вордстата сразу после установки, нужно просто обновить страницу и можно начинать работу. Его функции:
Прежде чем решить, какой плагин использовать, попробуйте в действии и тот и другой, это позволит вам сделать правильный выбор.
Для экономии времени при подборе ключевых слов часто пользуются специально предназначенными для этого автоматическими программами – парсерами, которые могут быть как платными, так и бесплатными.
Некоторые пацаны заказывают парсеры и чисто под свои нужды.
Лучший платный парсер Wordstat – KeyCollector. Используют его в основном те, кто профессионально занимается составлением семантики. Бесплатным аналогом КейКоллектора является программа Словоеб. Функции его урезаны, но составлять небольшие ядра с его помощью вполне реально.
Магадан тоже достаточно популярный парсер Вордстат, который тоже можно бесплатно скачать. Подбирает и анализирует запросы, есть поддержка регионов, предназначен для парсинга фраз Яндекс Директа.
Под конец хочу отметить, что Вордстат дает только те данные, которыми располагает Яндекс. Поэтому например частотность в Гугле и других поисковиках может быть совсем другая.
Ключевые слова в рассматриваемом нами аспекте – это слова и фразы, чётко отражающие суть того, что предлагается или того, о чём рассказывается на веб-странице. С их помощью пользователи Яндекса или иных поисковиков находят то, что им нужно. Грамотный их подбор к содержанию страницы дозволяет сделать страницу высоко посещаемой.
Нужно определиться, какие слова и типы запросов вводят интересующие читатели, покупатели или пользователи. Для этого надо войти в учётную запись и открыть Вордстат. Здесь показана статистика Яндекс Директ и прогнозирование количества запросов. Это очень удобный инструмент для анализа поиска пользователей, здесь можно посмотреть и подобрать нужные запросы, увидеть их статистику. Схожими функциями можно воспользоваться и при работе в Google AdWords, но для поисковой сети Google.
Выполнять объёмную работу таким способом довольно сложно. Ручной поиск в Wordstate осущевстляется только для оценки ниши. Для автоматизированного процесса можно пользоваться программами вроде Key Collector или Прогнозировщика ключей Яндекса.
Чтобы нужным образом конкретизировать ключевое слово, используются следующие операторы Яндекс Директ:
С помощью операторов ключевых слов и фраз можно подобрать типы соответствия последних:

Для удобного процесса подбора ключевых слов и фраз можно использовать один из двух схожих по функционалу плагинов – Yandex Wordstat Assistant и Yandex Wordstat Helper. С помощью первого можно осуществлять:

Вторая программа может осуществить только первые две функции.
Данные плагины можно загрузить в среде дополнений для Chrome и Firefox. После установки следует также войти в Яндекс.Вордстат (проверка сразу же покажет дополненный функционал) и действовать по данной инструкции:
Данные инструменты, не смотря на простоту и органичность, помогают сэкономить время за счёт и того факта, что сами работают без нареканий.
Подбор востребованных ключевых слов в Яндекс.Вордстат и Google AdWords, а также их «редактирование» при помощи соответствующих операторов помогают привлечь на сайты любой тематики достаточное количество заинтересованной в ней аудитории.
Всем привет! Сегодня я хочу рассказать о правилах работы с сервисом wordstat.yandex.ru, предоставляющего статистику поисковых запросов Яндекс. Этим сервисом я пользуюсь очень часто. В обязательном порядке перед написанием каждой статьи.
Дело в том, что важно не просто написать статью, но сделать это правильно с точки зрения поисковой оптимизации. Каждая статья должна быть заточена под определенное слово или словосочетание, которое называется ключевым или просто ключом. По этим ключевым словам пользователи находят ваш сайт, используя поисковые системы.
Фактически, ключ — это тот поисковый запрос, который вы продвигаете в поисковых системах в надежде, что по нему на ваш сайт будут приходить люди. Конечно, чтобы определиться с ними, просто необходимо иметь представление, сколько человек используют его за определенный интервал времени. Ведь если частота использования небольшая, то продвигать его совершенно бессмысленно.
Заметьте, что не всегда стоит выбирать самый часто используемый поисковый запрос, ибо конкуренция на них очень велика. Обязательно прочитайте о — эта информация позволит вам правильно подбирать ключевые слова для своего сайта.
Как известно, в России два флагмана поисковых систем — Яндекс и Google. Каждый из них предоставляет свой сервис для просмотра частотности поисковых запросов. Сегодня поговорим о статистике ключевых слов Яндекс — .
Сервис wordstat.yandex поддерживает пять фильтров, позволяющих получить исчерпывающую статистику по нужному ключевому слову.
1. По словам (используется по умолчанию). Слева указываем регион, в котором хотим посмотреть статистику показов данного поискового запроса по Яндексу.
Вводим нужное слово или словосочетание и жмем «Подобрать». Если не использовать дополнительные операторы, о которых я расскажу ниже, wordstat.yandex выдаст результат в виде двух списков. Левый список показывает статистику по запросам, содержащим изучаемое слово. Правый список покажет, что еще искали люди, использовавшие введенный вами запрос.

Главная ошибка заключается в том, что при отсутствии дополнительных операторов, wordstat.yandex выдаст число показов в месяц, которое соответствует всем поисковым запросам, в которых содержится введенное словосочетание в разных словоформах. Для конкретизации обязательно используйте операторы.
Словоформа — форма слова, полученная из основной части слова путем спряжения или склонения.
2. По регионам. Показывает статистику ключевых слов по регионам и городам. Можно выбрать отдельно статистику для городов и отдельно для регионов. Помимо вывода количества показов в месяц указывается еще одна величина — региональная популярность.

Название говорит само за себя: региональная популярность — это условная величина, измеряемая в процентах, показывающая популярность данного запроса в определенном регионе/городе.
3. На карте. Статистика ключевых слов от Яндекс по регионам, представленная уже не в виде таблицы, а визуально на карет Мира. Наводим курсор мыши на нужный регион и видим число показов в месяц и региональную популярность. Для увеличения масштаба жмем на страну и переходим к ее субъектам.

4. По месяцам. Помесячная статистика. Только не забудьте указать регион, для которого она будет выводиться. Информация выдается в виде графика, как в абсолютных, так и в относительных значениях (можно выбрать). График представляет собой ломанную. Координатами каждой вершины являются количество показов (по Y) и месяц (по X). Все это звучит несколько заумно, но на практике все очень просто. Только взгляните на рисунок.

5. По неделям. Идентичен предыдущему фильтру, только теперь временной интервал не месяц, а неделя.
Дополнительные операторы предназначены для настройки получаемой статистики. Давайте рассмотрим их с примерами, что все стало предельно понятно.
1. — (оператор «минус»). Оператор «-» ставится перед словом, которое следует исключить. Перед оператором ставится пробел.
Пример. Если указать в поиске игры -компьютерные , то получите статистику по всем запросам содержащим «игры» за исключением тех, что содержат «компьютерные». Можно исключать сразу несколько слов, поставив перед каждым из них оператор «-» (только не забудьте разделять их пробелами). Например, игры -компьютерные -настольные . Из результатов будут исключены все запросы, содержащие «компьютерные» или «настольные».
2. () (оператор группировки «скобки»), | (логический оператор «или»). При совместном использовании позволяют создать весьма сложные запросы.
Пример. Запрос сервер (уделенный | локальный) равнозначен сервер удаленный и сервер локальный .
3. "" (оператор «кавычки»). Очень важный оператор, который позволяет конкретизировать запрос. Будут учитываться только показы данного слова и его словоформ. Все запросы, включающие в себя дополнительные слова будут отсеяны.
Пример. Запрос «стол» . Будет выдано количество показов слов «столы», «столов», «стола», но исключены с дополнительным словом — «теннисный стол», «компьютерный стол» и другие.
4. + (оператор «плюс»). Ставится перед предлогами, чтобы они учитывались.
Пример. Установка wordpress +на denwer предлог «на» будет учитываться.
5. ! (оператор «восклицательный знак»). Слово, перед которым ставится оператор «!», учитывается в точном его написание. Все словоформы отсеиваются.
Из всех этих операторов чаще всего используются "" и!, позволяющие конкретизировать получаемую от Яндекс статистику. Скажем, результатом ввода «!установка!wordpress» будет количество показов запроса установка wordpress и никакого другого.
Казалось бы, на первый взгляд сервис wordstat.yandex.ru очень прост, но какой большой функционал в нем скрыт! Настоятельно рекомендую разобраться и освоить его.
Спасибо за внимание. Берегите себя!
Здравствуйте, уважаемые читатели блога сайт. Сегодня будет, наверное, довольно нудная статья про работу со статистикой поисковых запросов от Яндекс, Google и Рамблер. Ну, что может быть интересного в анализе частоты или количества вводимых пользователями в поисковики вопросов?
Поэтому получается, что если вы пишите статьи сами, то ваш проект просто обречен на успех и высокую посещаемость, львиную долю которой будут обеспечивать переходы с Яндекса и Google (поисковый трафик). Но, к сожалению, в реальном мире это далеко не так и всему виной та самая пресловутая статистика поисковых запросов, будь она неладна.
Дело в том, что статистика запросов Яндекса, Google или Рамблера (наибольшей популярностью пользуется обычно Вордстат) способна перечеркнуть все ваши попытки привлекать пользователей с поисковых систем за счет написания интересных, абсолютно уникальных статей, но оптимизированных вслепую под наугад выбранные запросы.
Именно так произошло с большей частью статей на моем блоге сайт, когда я все же решился на то, чтобы провести полный анализ всех ключевых слов, которые могут иметь отношение к моему блогу в статистике Яндекса.
Результаты меня по большей части расстроили, хотя и были некоторые удачные статьи, способные привлекать посетителей с сразу по огромному количеству ключевиков, зачастую имеющих очень высокую частоту. Но давайте все же начнем разбираться с проблемой учета данных статистики поисковых запросов Яндекса и в меньшей степени Google (ну, хотя эту систему, наверное, уже можно причислить к разряду живых мертвецов).
Проблема состоит в том, что работая вслепую (без предварительного составления хотя бы для той статьи, которую вы пишите в данный момент) вы можете здорово промахнуться и оптимизировать текст статьи и внутреннюю перелинковку (анкоры ссылок с других страниц своего сайта на продвигаемую страницу) совсем не под те поисковые запросы, которые смогут привести вам большое количество посетителей.
Промахнуться с интуитивным подбором перспективных запросов очень просто, но зато потом очень обидно будет видеть в статистике Яндекса или Google, что они оказались пустышками (т.е. пользователи поисковиков крайне редко используют именно такое сочетание ключевых слов в своих вопросах).
Нет, конечно же, если бы все вебмастера были в одинаковых условиях и ни у кого не было бы возможности просмотра и анализа статистики все в том же Яндексе, то и проблемы такой, наверное, не было бы. Но ведь статистика запросов пользователей поисковых систем доступна всем без ограничений и вы, не пользуясь ею, просто сами ставите себя в не выгодные условия.
Не стоит слушать «троллей», которые кричат о том, что вы опустили свой СДЛ (проект для людей) до уровня ГС (проекта для заработка, рассчитанного на недолгий жизненный цикл) составив предварительно маленькое семантическое ядро для будущей статьи, используя для этого онлайн сервисы статистики поисковых запросов Яндекса или Google и Рамблер.
Это они от зависти или от свой природы «тролля». Но не стоит заспамливать ключевыми словами текст статьи — в этом случае вы можете все испортить.
Давайте сначала я приведу фактическую информацию, а уже потом налью воды по поводу своего опыта работы со статистикой поисковых запросов, в основном Яндекса (писать кратко не умею, поэтому будет много букв; извините, но мне показалось, что это все важно). Итак, факты. Как вы думаете, зачем поисковикам типа Яндекса, Google или Рамблер давать вам возможность копаться в их статистике?
Ведь оптимизаторы (Seo-шники) всегда были по другую сторону баррикад по отношению к поисковым системам. Знаете почему? Тут нет места всяким там принципиальным соображениям или же идеологиям. Все банально просто и упирается, как и следовало ожидать, в деньги, ибо оптимизаторы отбирают у поиска часть их основного источника дохода от контекстной рекламы. Большое количество потенциальных клиентов Директа или Adwords получают посетителей на свои проекты с помощью услуг оптимизаторов (сеошников).
Поэтому выглядит очень странно, что Яндекс и Гугл открывают оптимизаторам (нам с вами) доступ к статистике поисковых запросов. Ответ тут опять же завязан на основной способ заработка поисковиков — контекстную рекламу. Дело в том, что рекламодателям контекста нужна эта информация для составления наиболее или Google Adwords. Именно благодаря им эта статистика запросов доступна и нам тоже, и грех будет ей не воспользоваться в своих личных (шкурных) интересах.
На мой непрофессиональный взгляд можно выделить три или даже четыре основных источника получения прямой (есть сервисы, которые собирают данные с этих сервисов в автоматическом режиме — парсят их) статистики поисковых запросов:

Я не профессиональный сеошник, поэтому мне для понимания общей картины и составления семантического ядра вполне достаточно статистики Яндекса, хотя возможно, что при продвижении проекта по очень высокочастотным фразам будет иметь смысл в уточнении данных в сервисах Рамблера или Google, но мне этого не требуется.
Немножко теории. Поисковые запросы и ключевые слова очень часто путают между собой, поэтом попробую внести ясность. Поисковый запрос — это набор слов, которые набирает любой пользователь в строке поиска. Существуют наборы слов, которые ищут очень часто (высокочастотные запросы или ВЧ), существуют менее популярные сочетания слов (среднечастотные или СЧ), ну и, естественно, есть редко встречающиеся наборы слов (низкочастотные или НЧ).
Я не провожу для себя четкой границы между этими запросами по частоте их показов, но обычно считают, что если набор слов имеет частоту свыше 10 000 показов в месяц, то он высокочастотный. Если фраза имеет частоту ниже 1 000 показов в месяц, то это НЧ, ну а СЧ лежит где-то посередине. Но цифры эти более чем условны и сильно зависят от тематики.
Понятно, что лучше всего выбирать для будущего семантического ядра более частотные запросы, ибо в случае попадания на первую страницу поисковой выдачи вы получите очень большой приток посетителей. Но вот продвинуться по ВЧ или СЧ будет скорее всего очень сложно, ибо наверняка найдется масса других таких же умных как вы вебмастеров.
Поэтому при подборе поисковых запросов для будущего семантического ядра, как сайта целиком, так и для отдельной статьи, следует правильно рассчитывать свои силы — в противном случае можно вообще не получить ни одного посетителя по ВЧ, т.к. вам не удастся пробиться даже близко к Топ 10 (первая страница выдачи).
Правда, не всегда будет много желающих продвигаться по высокочастотным и среднечастотным запросам. Бывают случаи, когда конкуренция по ВЧ и СЧ довольно низкая и шансы пробиться есть у всех. Тут нужно смотреть и анализировать те сайты, которые находятся в Топе по выбранному вами запросу. Если там не очень трастовые ресурсы, то можно будет попробовать побороться.
Когда мы подошли уже непосредственно к оптимизации, то вот тут речь и заходит про , которые представляют по сути отдельные слова из выбранных вами запросов, по которым вы будете пытаться продвинуться и попасть в Топ (первая десятка сайтов в выдаче).
Очень часто десяток выбранных (в качестве семантического ядра) для данной конкретной статьи поисковых запросов могут состоять всего лишь из нескольких ключевых слов, которые вам и нужно будет N-ное количество раз употребить в тексте статьи и обязательно включить их в Title. Причем, в начало Title включите слова более частотного запроса и дальше по убывающей. Например, семантическое ядро этой статьи, можно сказать, состоит из:

Частотность пробивал по статистике Яндекса, заключая приведенные слова и словосочетания в кавычки, чтобы отсеять очевидные пустышки. Т.е. я набрал для начала что-то вроде «статистика запросов» и получил кучу возможных вариантов с этими словами, а так же кучу ассоциативных запросов в правой колонке. Каждый из предложенных вариантов я проверил на реальную частоту показов с помощью заключения его в кавычки и в результате получил приведенный чуть выше список.
Как вы можете видеть, при всем богатстве фраз из семантического ядра статьи, ключевых слов, под которые мне следует оптимизировать текст, не так уж и много. Теперь нужно только составить правильный Title для страницы со статьей, чтобы в его начале стояли ключи из наиболее частотного запроса, и употребить каждое ключевое слово в статье от одного до двух процентов от общего числа слов в статье.
Бойтесь заспамить текст и довести плотность вхождения ключей до 3 и более процентов — возможно исключение статьи из . Ключевые слова лучше употреблять в разных словоформах (не надо пытаться впихнуть в текст одни лишь прямые вхождения), в соответствии с логикой вашего повествования. Я как-то упоминал тот онлайн сервис, где можно провести статьи на плотность вхождения ключей.

Как видите, у этой статьи вроде бы все в порядке, разве что только частоту первого слова (не привожу его, что бы еще больше не увеличить плотность его вхождения), надо бы уменьшить. На показатель тошноты можете не обращать внимания, т.к. он вычисляется там как квадратный корень из самого часто употребляемого слова, а значит, чем больше будет текст, тем выше будет тошнота, что не логично. Да и вообще, тошнота уже канула в лету.
Еще раз подытожим. После того, как вы набросаете на листочке те запросы (анализ статистики в Яндексе обычно занимает несколько минут), с которых вы рассчитываете получить приток посетителей, вам нужно будет вычленить из этого семантического ядра статьи ключевые слова и обязательно употребить их в Title продвигаемой страницы (чем больше частота — тем ближе к началу тега Title) и употребить выбранные из семантического ядра ключевые слова в тексте статьи с частотой от 1 до 2 процентов от общего их количества.
Признаюсь, что писать статьи с учетом статистики запросов Яндекс я начал только чуть менее года назад, а делать это с полностью открытыми глазами — только около месяца назад. И причина тому совсем не лень (ее у меня не много), а скорее некоторая косность (не гибкость) по отношению к чему-то новому. Ну, типа, всегда так делал и дальше буду продолжать в том же духе.
Но иногда нужно перевести дух, оглядеться и понять, в том ли направлении вы движетесь. Вот именно использование Вордстата для анализа своего проекта и позволяет оглядеться и изменить при необходимости направление движения. Последние пару недель я занимаюсь тем, что пытаюсь выудить из статистики Яндекса все варианты, которые могут иметь отношение к моему блогу.
Делаю я это вручную, что довольно утомительно, но зато у меня постепенно складывает понимание общей картины всей этой кухни (открываются глаза). Мозг при этом уже плавится, но анализ затягивает и постепенно выявляет явные промахи, а так же позволяет определить тематику будущих статьей , ибо то, что чаще всего набирают пользователи в поисковиках, их больше всего и интересует. А идти в ногу с пожеланиями будущих читателей это, по-моему, прямой путь к успешному развитию проекта.
Кстати, проводя анализ своего проекта с помощью статистики запросов Яндекса, может понадобиться узнать, а имеет ли ваш сайт уже какие-либо позиции по интересующему вас слову или словосочетанию. Для этого я использую возможности программы , о которой уже писал, но забыл упомянуть о возможности определения видимости сайта по нужным вам ключам с помощью этой замечательной программы.
Вам нужно будет перейти на вкладку «Подбор» программы Site Auditor, ввести интересующие вас слова в области «Проверить» и нажать на стрелочку, расположенную справа. Вас перебросит на вкладку «Видимость сайта», где вам нужно будет ввести URL своего ресурса и нажать на кнопку «Проверить».
В результате вы увидите позиции вашего сайта по интересующему ключевому слову в поисковых системах Яндекс и Гугл. Если позиций не появилось, то значит ваш проект занимает место в выдаче ниже пятидесятого.

Удачи вам! До скорых встреч на страницах блога сайт
посмотреть еще ролики можно перейдя на");">

Вам может быть интересно
 Учет морфология языка и другие проблемы решаемые поисковыми системами, а так же отличие ВЧ, СЧ и НЧ запросов
Учет морфология языка и другие проблемы решаемые поисковыми системами, а так же отличие ВЧ, СЧ и НЧ запросов
 Яндекс Вордстат и семантическое ядро - подбор ключевых слов для сайта с помощью статистики онлайн-сервиса Wordstat.Yandex.ru
Яндекс Вордстат и семантическое ядро - подбор ключевых слов для сайта с помощью статистики онлайн-сервиса Wordstat.Yandex.ru
 Внутренняя оптимизация - подбор ключевых слов, проверка тошноты, оптимальный Title, дублирование контента и перелинковка под НЧ
Внутренняя оптимизация - подбор ключевых слов, проверка тошноты, оптимальный Title, дублирование контента и перелинковка под НЧ
 Способы оптимизации контента и учет тематики сайта при ссылочном продвижении для сведения затрат к минимуму
Способы оптимизации контента и учет тематики сайта при ссылочном продвижении для сведения затрат к минимуму
 Как добавить сайт в аддурилки (add url) Яндекса, Google и других поисковиков, регистрация в панелях для вебмастеров и каталогах
Как добавить сайт в аддурилки (add url) Яндекса, Google и других поисковиков, регистрация в панелях для вебмастеров и каталогах
 СЕО терминология, сокращения и жаргон
СЕО терминология, сокращения и жаргон
Всё, что нужно - почтовый аккаунт на Яндексе. Регистрация занимает всего пару минут.
По умолчанию Wordstat ищет по словам. Впишите в поиск ключевик и нажмите «Подобрать». Вы увидите разные запросы с данным словом и его словоформами.

Справа от каждого - частотность. Её значение основывается на данных за последние 30 дней и учитывает поиск в Яндексе.
Важные моменты по частотности:
Вордстат предлагает фильтры по устройствам:
Сервис автоматически учитывает все падежи и числа и разбивает фразы на слова. Так, по запросу «галстук бабочка» выходит и «как завязывать галстук бабочку», и «купить бабочку галстук +в москве».
Wordstat также подбирает слова, которые пользователи вводили вместе с текущим запросом:

Если у вас моно-товар, который отличается по размеру, цвету, как в примере выше, правая колонка выдает различные вариации. Если запрос более обширный, как правило, это относится к сфере услуг, вы увидите несвязанные напрямую варианты. Например, выдача по фразе «Ремонт квартир»:

Это шанс выяснить:
Если кликнуть на любую фразу, она появляется в строке поиска - и сервис выдает прогнозируемое число показов в месяц по ней.
Под результатами - переход на следующие страницы выдачи. К сожалению, нельзя попасть в конец по одному клику. Нужно перелистывать каждую страницу по кнопке «Далее».
Для суперпопулярных запросов сервис не показывает данные, расположенные дальше 40-й страницы. Например, по фразе «скачать торрент» свыше 32 миллионов запросов.
Выход - сторонние решения для парсинга. Самые популярные: Key Collector, YandexKeyParser, расширения Yandex Wordstat Helper и Yandex Wordstat Assistant (о них - в конце статьи).
Операторы помогают искать фразы по разным типам соответствия. Сравните количество показов:
Для большей смысловой детализации результатов есть вспомогательный синтаксис:




Когда основной запрос двухсловный и нужны 4-словные варианты, пишем так:

Wordstat сортирует результаты по географии. Нажмите «Все регионы» и отметьте нужные:

Для четырех часто используемых вариантов есть опция «Быстрый выбор».
Галочка «по регионам» помогает оценить популярность запроса в конкретном регионе или городе. Более 100% - это повышенный интерес:

При необходимости можно посмотреть частоту использования слов на карте мира:

Функция «История запросов» показывает динамику на основе данных за последние два года.
Выдача на большинство тематик зависит от сезона. Если в Вордстате нет нужной семантики, возможно, она появится в выдаче, когда наступит соответствующий сезон.
По запросам «новости» или «куда пойти» вы постоянно получаете разные списки.

По умолчанию выходят график и таблица по месяцам, но можно переключить на недели. В них - абсолютные (число показов по запросу) и относительные значения (его отношение к общему числу показов в Яндексе).

Еще одна фишка. По резким скачкам за короткий период можно выявить накрутку показов вебмастерами. Характерный признак - за отдельный короткий период фраза набирает тысячи, за остальные - 0.
Итак, теперь вы знаете, как получать семантику из Вордстата, с уточнением по значению, географии и сезонности. Далее рассмотрим, что с ними делать и как на примере. А именно - подберем СЯ из реальных данных сервиса.
По оценкам экспертов, ручной парсинг в Wordstat дает 30-40% всех фраз. Но с учетом, что сервис бесплатный, это очень даже неплохо. Дополнительно можно генерировать ключевые слова по поисковым подсказкам и с помощью других инструментов.
Пример: спрос на деревянные окна.
1) Определяем, как пользователи формулируют запрос. Открываем wordstat.yandex.ru и вбиваем фразу:

Результатов слишком много. Вручную их прорабатывать займет кучу времени. При этом среди них есть нерелевантные - «окна в деревянном доме», «деревянные наличники», «деревянные окна своими руками» и подобные.
Необходимо уточнить формулировку. Первым делом избавимся от «мусора» с помощью минус-слов: дом, наличники, своими руками, старые, жалюзи, как, утеплить, потеют.
2) Настраиваем регион - город Пермь - и тип устройств, с которых заходят потенциальные клиенты. Допустим, нас интересуют все пользователи, так как мы собираемся запускать кампании в мобайле и на десктопе:

3) Определяем целевой спрос. Для этого отбираем релевантные варианты из выдачи и заносим в таблицу Excel по разным сегментам.
В идеале нужно проработать все страницы, чтобы учесть все нюансы и составить более полную картину о потребностях целевой аудитории. Для простоты рассмотрим на примере первой:

На скриншоте серым цветом обозначены фразы, которые мы исключаем, так как они не подходят.
4) Просматриваем похожие фразы. Некоторые из них попадают в целевой спрос, например:

Можно также посмотреть второй столбец для подходящих слов, которые определили в пункте 3, и дополнить таблицу.
В итоге мы получаем определенное количество ключевых слов. Парсинга в Вордстате недостаточно. Семантическое ядро можно расширить с помощью более сложных платных и бесплатных инструментов. Кроме того, они автоматизируют дальнейшую работу с сервисом Wordstat.
Примеры:
Вводить отдельные запросы для каждой фразы - это огромные затраты времени. Но от этого никуда не уйти. Зато есть решения, которые значительно упростят и ускорят работу с сервисом.












