Урок посвящен тому, как решать 5 задание ЕГЭ по информатике
5-я тема характеризуется, как задания базового уровня сложности, время выполнения – примерно 2 минуты, максимальный балл — 1
Пример:
Зашифруем буквы А, Б, В, Г при помощи двоичного кодирования равномерным кодом и посчитаем количество возможных сообщений:
Таким образом, мы получили равномерный код
, т.к. длина каждого кодового слова одинакова для всех кодов
(2).
Декодирование (расшифровка) - это восстановление сообщения из последовательности кодов.
Для решения задач с декодированием, необходимо знать условие Фано:
Условие Фано: ни одно кодовое слово не должно являться началом другого кодового слова (что обеспечивает однозначное декодирование сообщений с начала)
Префиксный код - это код, в котором ни одно кодовое слово не совпадает с началом другого кодового слова. Сообщения при использовании такого кода декодируются однозначно.

Однозначное декодирование обеспечивается:



ЕГЭ 5.1: Для кодирования букв О, В, Д, П, А решили использовать двоичное представление чисел 0 , 1 , 2 , 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления).
Закодируйте последовательность букв ВОДОПАД таким способом и результат запишите восьмеричным кодом.
Результат: 22162
Решение ЕГЭ данного задания по информатике, видео:
Рассмотрим еще разбор 5 задания ЕГЭ:
ЕГЭ 5.2: Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв - из двух бит, для некоторых - из трех). Эти коды представлены в таблице:
| a | b | c | d | e |
|---|---|---|---|---|
| 000 | 110 | 01 | 001 | 10 |
Какой набор букв закодирован двоичной строкой 1100000100110 ?
✎ 1 вариант решения:
Результат: b a c d e.
✎ 2 вариант решения:
 110
000 01
001 10
110
000 01
001 10
Результат: b a c d e.
Кроме того, вы можете посмотреть видео решения этого задания ЕГЭ по информатике:
Решим следующее 5 задание:
ЕГЭ 5.3:
Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4 , и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23 , то получим последовательность 0010100110).
Определите, какое число передавалось по каналу в виде 01100010100100100110 .
Ответ: 6 5 4 3
Вы можете посмотреть видео решения этого задания ЕГЭ по информатике:
ЕГЭ 5.4:
Для кодирования некоторой последовательности, состоящей из букв К, Л, М, Н решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0 , для буквы К - кодовое слово 10 .
Какова наименьшая возможная суммарная длина всех четырёх кодовых слов?
✎ 1 вариант решения основан на логических умозаключениях:
✎ 2 вариант решения :
 (Н) -> 0 -> 1 символ
(К) -> 10 -> 2 символа
(Л) -> 110 -> 3 символа
(М) -> 111 -> 3 символа
(Н) -> 0 -> 1 символ
(К) -> 10 -> 2 символа
(Л) -> 110 -> 3 символа
(М) -> 111 -> 3 символа
Ответ: 9
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 2 (под редакцией Крылова С.С., Чуркиной Т.Е.):
По каналу связи передаются сообщения, содержащие только 4 буквы: А, Б, В, Г; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв А, Б, В используются такие кодовые слова: А: 101010 , Б: 011011 , В: 01000 .
Г, при котором код будет допускать однозначное декодирование. наименьшим числовым значением.
Результат: 00
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 16 (под редакцией Крылова С.С., Чуркиной Т.Е.):
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приемной стороне канала связи. Использовали код: А — 01 , Б — 00 , В — 11 , Г — 100 .
Укажите, каким кодовым словом должна быть закодирована буква Д.
Длина
этого кодового слова должна быть наименьшей
из всех возможных. Код должен удовлетворять свойству однозначного декодирования. Если таких кодов несколько, укажите код с наименьшим числовым значением.
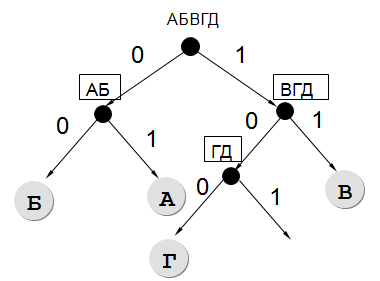
Результат: 101
Подробней разбор урока можно посмотреть на видео ЕГЭ по информатике 2017:
ЕГЭ по информатике 5 задание 2017 ФИПИ вариант 17 (Крылов С.С., Чуркина Т.Е.):
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д и Е, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приемной стороне канала связи. Использовали код: А — 0 , Б — 111 , В — 11001 , Г — 11000 , Д — 10 .
Укажите, каким кодовым словом должна быть закодирована буква Е. Длина этого кодового слова должна быть наименьшей из всех возможных. Код должен удовлетворять свойству однозначного декодирования. Если таких кодов несколько, укажите код с наименьшим числовым значением.
 1 - не подходит (все буквы кроме А начинаются с 1)
10 - не подходит (соответствует коду Д)
11 - не подходит (начало кодов Б, В и Г)
100 - не подходит (код Д - 10 - является началом данного кода)
101 - не подходит (код Д - 10 - является началом данного кода)
110 - не подходит (начало кода В и Г)
111 - не подходит (соответствует коду Б)
1000 - не подходит (код Д - 10 - является началом данного кода)
1001 - не подходит (код Д - 10 - является началом данного кода)
1010 - не подходит (код Д - 10 - является началом данного кода)
1011 - не подходит (код Д - 10 - является началом данного кода)
1100 - не подходит (начало кода В и Г)
1101 - подходит
1 - не подходит (все буквы кроме А начинаются с 1)
10 - не подходит (соответствует коду Д)
11 - не подходит (начало кодов Б, В и Г)
100 - не подходит (код Д - 10 - является началом данного кода)
101 - не подходит (код Д - 10 - является началом данного кода)
110 - не подходит (начало кода В и Г)
111 - не подходит (соответствует коду Б)
1000 - не подходит (код Д - 10 - является началом данного кода)
1001 - не подходит (код Д - 10 - является началом данного кода)
1010 - не подходит (код Д - 10 - является началом данного кода)
1011 - не подходит (код Д - 10 - является началом данного кода)
1100 - не подходит (начало кода В и Г)
1101 - подходит
Результат: 1101
Более подробное решение данного задания представлено в видеоуроке:
5 задание. Демоверсия ЕГЭ 2018 информатика (ФИПИ):
По каналу связи передаются шифрованные сообщения, содержащие только десять букв: А, Б, Е, И, К, Л, Р, С, Т, У. Для передачи используется неравномерный двоичный код. Для девяти букв используются кодовые слова.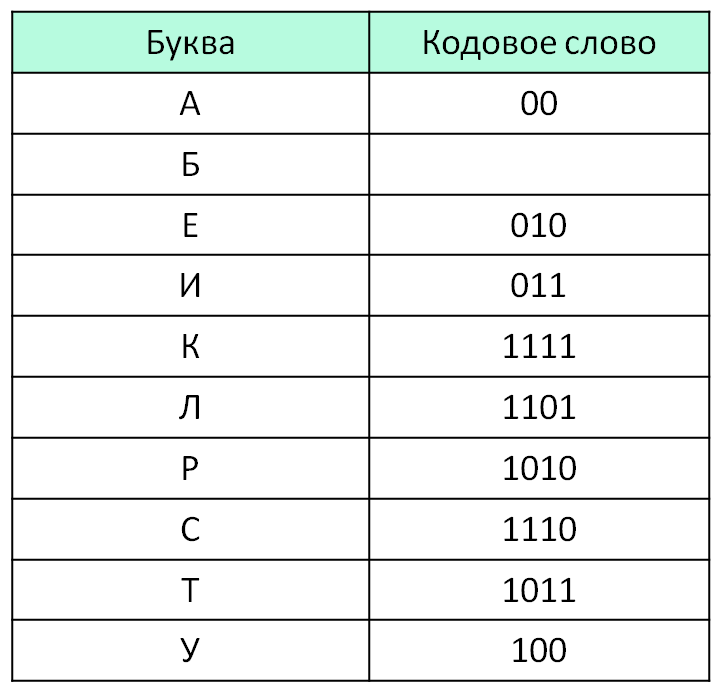
Укажите кратчайшее кодовое слово для буквы Б
, при котором код будет удовлетворять условию Фано.
Если таких кодов несколько, укажите код с наименьшим
числовым значением.

Результат: 1100
Подробное решение данного 5 задания из демоверсии ЕГЭ 2018 года смотрите на видео:
Задание 5_9. Типовые экзаменационные варианты 2017. Вариант 4 (Крылов С.С., Чуркина Т.Е.):
По каналу связи передаются шифрованные сообщения, содержащие только четыре букв: А, Б, В, Г; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв А , Б , В используются кодовые слова:
А: 00011 Б: 111 В: 1010
Укажите кратчайшее кодовое слово для буквы Г
, при котором код будет допускать однозначное декодирование.
Если таких кодов несколько, укажите код с наименьшим
числовым значением.

Результат: 00
Задание 5_10. Тренировочный вариант №3 от 01.10.2018 (ФИПИ):
По каналу связи передаются сообщения, содержащие только буквы: А, Е, Д, К, М, Р ; для передачи используется двоичный код, удовлетворяющий условию Фано. Известно, что используются следующие коды:
Е – 000 Д – 10 К – 111
Укажите наименьшую возможную длину закодированного сообщения ДЕДМАКАР
.
В ответе напишите число – количество бит.
 Д Е Д М А К А Р
10 000 10 001 01 111 01 110
Д Е Д М А К А Р
10 000 10 001 01 111 01 110
Результат: 20
Смотрите виде решения задания:
Рассмотрим другую кодовую таблицу: А Б В Г Д 000 01 10 011 100 Здесь условие Фано не выполняется, поскольку код буквы Б (01) является началом кода буквы Г (011), а код буквы Д (100) начинается с кода буквы В (10). Тем не менее, можно заметить, что выполнено «обратное» условие Фано: ни один код не является окончанием другого кода (такой код называют постфиксным). Поэтому закодированное сообщение можно однозначно декодировать с конца. Например, рассмотрим цепочку 011000110110. Последней буквой в этом сообщении может быть только В (код 10): В 0110001101 10 Вторая буква с конца – Б (код 01): Б В 01100011 01 10 и так далее: Б Д Г Б В 01 100 011 01 10.
Слайд 26 из презентации «Методы кодирования информации» . Размер архива с презентацией 734 КБ.«Двоичное кодирование» - Цифры. Двоичное кодирование текстовой информации. Таблица кодировки. Информационный объем текста. Двоичное кодирование в компьютере. Кодирование текстовой информации. Таблица расширенного кода. Символ. Уникальный двоичный код. Буква латинского алфавита. Использование двоичной системы. Компьютеры.
«Кодирование информации в двоичном коде» - Определение. Системы счисления. Двоичная система счисления. Кодирование. Кодирование информации. Приведите примеры кодирования. Десятичная система счисления. Значение цифры. Значение цифры зависит от ее положения. Алфавит. Языки. Римская непозиционная система. Двоичное кодирование. Что здесь зашифровано.
«Способы кодирования» - Номер столбца. Буква исходного текста. Кодирование информации. Способы кодирования информации. Декодируйте информацию. Передаваемая информация. В мире кодов. Автоматическое кодирование. Метод координат. Достоинства и недостатки. Разнообразие кодов. Мальчик. Как можно назвать записную книжку с точки зрения хранения информации. Закодированный текст. Носитель информации. Ключевые слова. Разгадайте ребус.
«Способы кодирования информации» - В памяти компьютера информация представлена в двоичном коде. Кодирование и декодирование. Можно закодировать информацию. Способы кодирования информации. Составим простейшую кодовую таблицу. Чтобы узнать зашифрованное слово, возьмите только первые слоги. Что прочитал Лом на флагах встречной шхуны. Придумайте собственный способ кодирования букв русского алфавита. Задания. Зашифрованная информация. Луи Брайль придумал специальный способ представления информации.
«Методы кодирования информации» - Двоичное кодирование в компьютере. Количество информации. Оптический телеграф Шаппа. Условие Фано. Какой код использовать. Получено сообщение. «Да» или «Нет». Первый телеграф. Способы кодирования информации. Запись информации. Почему двоичное кодирование. Сигнальные флаги. Кодирование. Кодирование и декодирование. Кодирование информации. Выбор способа кодирования. Виды информации. Сколько вариантов.
Задание №5Условие Фано названо в честь его создателя, итальянско-американского ученого Роберта Фано. Условие является необходимым в теории кодирования при построении самотерминирующегося кода. Учитывая другую терминологию, такой код называется префиксным.
Сформулировать данное условие можно следующим образом: « ни одно кодовое слово не может выступать в качестве начала любого другого кодового слова ».
С математической точки зрения условие можно сформулировать следующим образом: « если код содержит слово B, то для любой непустой строки C слова BC не существует в коде ».
В чем смысл обратного условия Фано?
Существует также и обратное правило Фано, формулировка которого звучит следующим образом: « ни одно кодовое слово не может выступать в качестве окончания любого другого кодового слова ».
С математической точки зрения обратное условие можно сформулировать следующим образом: « если код содержит слово B, то для любой непустой строки C слова CB не существует в коде ».
Условие задачи: дана последовательность, которая состоит из букв «A», «B», «C», «D» и «E». Для кодирования приведенной последовательности применяется неравномерный двоичный код, при помощи которого можно осуществить однозначное декодирование.
Буква
Двоичный эквивалент
010
011
101
111
Вопрос : есть ли возможность для одного из символов сократить длину кодового слова таким образом, чтобы сохранить возможность однозначного декодирования? При этом коды остальных символов должны остаться неизменными.
Номер варианта
Ответ
B – 01
Не представляется возможным
C – 01
D – 01
Решение : для того, чтобы сохранилась возможность декодирования, достаточным является соблюдение прямого или обратного условия Фано . Проведем последовательную проверку вариантов 1, 3 и 4. В случае если ни один из вариантов не подойдет, правильным ответом будет вариант 2 (не представляется возможным).
Вариант 1. Код: A - 00, B - 01, C - 011, D - 101, и E - 111. Прямое условие Фано не выполняется: код символа «B» совпадает с началом кода символа «C». Обратное правило Фано не выполняется: код символа «B» совпадает с окончанием кода символа «D». Вариант не является подходящим.
Вариант 3. Код: A - 00, B - 010, C - 01, D - 101, и E - 111. Прямое условие Фано не выполняется: код символа «C» совпадает с началом кода символа «B». Обратное условие также не выполняется: код символа «C» совпадает с окончанием кода символа «D». Вариант не является подходящим.
Вариант 4. Код: A - 00, B - 010, C - 011, D - 01, и E - 111. Прямое условие Фано не выполняется: код символа «D» совпадает с началом кода символов «B» и «C». Однако наблюдается выполнение обратного правила Фано: код символа «D» не совпадает с окончанием кода всех остальных символов. По этой причине, вариант является подходящим.
После проверки вариантов решения задачи на соответствие прямому и обратному условию Фано , было установлено, что правильным является вариант 4.
Ответ : 4
Код Хаффмана
Идея, положенная в основу кодирования Хаффмана, основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код. Это нужно, так как мы хотим, чтобы, когда мы обработали весь ввод, самые частотные символы заняли меньше всего места (и меньше, чем они занимали в оригинале), а самые редкие - побольше (но так как они редкие, это не имеет значения).
№ 1. Для кодирования букв О, В, Д, П, А решили использовать двоичное представление чисел 0, 1, 2, 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления). Если закодировать последовательность букв ВОДОПАД таким способом и результат записать восьмеричным кодом, то получится
1) 22162
2) 1020342
3) 2131453
4) 34017
Пояснение.
Сначала следует представить данные в условии числа в двоичном коде:
100
Затем закодировать последовательность букв: ВОДОПАД - 010010001110010. Теперь разобьём это представление на тройки справа налево и переведём полученный набор чисел в десятичный код, затем в восьмеричный (восьмеричное предствление совпадает с десятичным при разбиении тройками)
010 010 001 110 010 - 22162.
№ 2. Для передачи по каналу связи сообщения, состоящего только из символов А, Б, В и Г, используется посимвольное кодирование: А-00, Б-11, В-010, Г-011. Через канал связи передаётся сообщение: ВБГАГВ. Закодируйте сообщение данным кодом. Полученное двоичное число переведите в шестнадцатеричный вид.
1) CBDADC
2) 511110
3) 5В1А
4) А1В5
Пояснение.
Закодируем последовательность букв: ВБГАГВ - 0101101100011010. Теперь разобьём это представление на четвёрки справа налево и переведём полученный набор чисел сначала в десятичный код, затем в шестнадцатеричный:
0101 1011 0001 1010 - 5 11 1 10 - 5В1А.
Правильный ответ указан под номером 3
№ 3. Для кодирования сообщения, состоящего только из букв А, Б, В и Г, используется неравномерный по длине двоичный код:
010
011
Если таким способом закодировать последовательность символов ВГАГБВ и записать резуль получится:
1) CDADBC
2) A7C4
3) 412710
4) 4С7А
Пояснение.
Закодируем последовательность букв: ВГАГБВ - 0100110001111010. Теперь разобьём это представление на четвёрки справа налево и переведём полученный набор чисел сначала в десятичный код, затем в шестнадцатеричный:
0100 1100 0111 1010 - 4 12 7 10 - 4С7А.
Правильный ответ указан под номером 4.
№ 4. Черно-белое растровое изображение кодируется построчно, начиная с левого верхнего угла и заканчивая в правом нижнем углу. При кодировании 1 обозначает черный цвет, а 0 – белый.
Для компактности результат записали в восьмеричной системе счисления. Выберите правильную запись кода.
1) 57414
2) 53414
3) 53412
4) 53012
Пояснение.
Код первой строки: 10101.
Код второй строки: 11000.
Код третьей строки: 01010.
Запишем коды по порядку в одну строку: 101011100001010. Теперь разобьём это представление на тройки справа налево и переведём полученный набор чисел в десятичный код (восьмеричное представление совпадает с десятичным при разбиении тройками).
101 011 100 001 010 - 53412.
№ 5. Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв - из двух бит, для некоторых - из трех). Эти коды представлены в таблице:
000
110
001
Определите, какой набор букв закодирован двоичной строкой 1100000100110
1) baade
2) badde
3) bacde
4) bacdb
Пояснение.
Мы видим, что выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова, поэтому однозначно можем раскодировать сообщение с начала.
Разобьём код слева направо по данным таблицы и переведём его в буквы:
110 000 01 001 10 - b a c d e.
Правильный ответ указан под номером 3.
№ 6. Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4, и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23, то получим последовательность 0010100110). Определите, какое число передавалось по каналу в виде 01100010100100100110?
1) 6543
2) 62926
3) 62612
4) 3456
Пояснение.
Из примера видно, что 2 знака кодируются 10 двоичными разрядами (битами), на каждую цифру отводится 5 бит. В условии сказано, что каждая цифра записывается кодом длиной 4 знака, значит, пятую цифру можно откинуть.
Разобьём двоичную запись на группы по 5 знаков: 01100 01010 01001 00110. Отбрасываем послеюднюю цифру в каждой пятёрке и переводим в десятичную запись:
0110 0101 0100 0011 - 6 5 4 3.
Правильный ответ указан под номером 1.
№ 7. По каналу связи передаются сообщения, содержащие только 4 буквы - П, О, Р, Т. Для кодирования букв используются 5-битовые кодовые слова:
П - 11111, О - 11000, Р - 00100, Т - 00011.
Для этого набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трёх позициях.
Это свойство важно для расшифровки сообщений при наличии помех (в предположении, что передаваемые биты могут искажаться, но не пропадают). Закодированное сообщение считается принятым корректно, если его длина кратна 5 и каждая пятёрка отличается от некоторого кодового слова не более чем в одной позиции; при этом считается, что пятёрка кодирует соответствующую букву. Например, если принята пятерка 00000, то считается, что передавалась буква Р.
Среди приведённых ниже сообщений найдите то, которое принято корректно, и укажите его расшифровку (пробелы несущественны).
11011 11100 00011 11000 01110
00111 11100 11110 11000 00000
1) ПОТОП
2) РОТОР
3) ТОПОР
4) ни одно из сообщений не принято корректно
Пояснение.
Длина обоих сообщений кратна пяти.
Анализируя первое сообщение "11011 11100 00011 11000 01110", приходим к выводу, что оно принято некорректно, поскольку нет такого слова, которое бы отличалось от слова "01110" только в одной позиции.
Рассмотрим второе сообщение. Учитывая, что каждая пятёрка отличается от некоторого кодового слова не более чем в одной позиции, его возможно расшифровать только как "ТОПОР".
№ 8. Для передачи данных по каналу связи используется 5-битовый код. Сообщение содержит только буквы А, Б и В, которые кодируются следующими кодовыми словами:
А - 10010, Б - 11111, В - 00101.
При передаче возможны помехи. Однако некоторые ошибки можно попытаться исправить. Любые два из этих трёх кодовых слов отличаются друг от друга не менее чем в трёх позициях. Поэтому если при передаче слова произошла ошибка не более чем в одной позиции, то можно сделать обоснованное предположение о том, какая буква передавалась. (Говорят, что «код исправляет одну ошибку».) Например, если получено кодовое слово 00100, считается, что передавалась буква В. (Отличие от кодового слова для Б только в одной позиции, для остальных кодовых слов отличий больше.) Если принятое кодовое слово отличается от кодовых слов для букв А, Б, В более чем в одной позиции, то считается, что произошла ошибка (она обозначается "х").
Получено сообщение 10000 10101 11001 10111. Декодируйте это сообщение - выберите правильный вариант.
1) АВББ
2) хххх
3) АВхБ
4) АххБ
Пояснение.
Декодируем каждое слово сообщения. Первое слово: 10000 отличается от буквы А только одной позицией. Второе слово: 10101 отличается от буквы В только одной позицией. Третье слово: 11001 отличается от любой буквы более чем в одной позиции. Четвёртое слово: 10111 отличается от буквы Б только одной позицией.
Ответ: АВхБ.
№ 9. Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В и Г использовали такие кодовые слова: А - 111, Б - 110, В - 101, Г - 100.
Укажите, каким кодовым словом из перечисленных ниже может быть закодирована буква Д. Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
1) 1
2) 0
3) 01
4) 10
Пояснение.
Для того, чтобы сообщение, записанное с помощью неравномерного по длине кода, однозначно раскодировалось, требуется, чтобы никакой код не был началом другого (более длинного) кода. Рассмотрим варианты для буквы Д, начиная с самого короткого.
1) Д=1: код буквы Д является началом всех представленных кодов букв, поэтому этот вариант не подходит.
2) Д=0: код буквы Д не является началом другого кода, поэтому этот вариант подходит.
3) Д=01: код буквы Д не является началом другого кода, поэтому этот вариант подходит.
4) Д=10: код буквы Д является началом кодов букв В и Г, следовательно, этот вариант не подходит.
Таким образом, подходят два варианта: 0 и 01. 0 короче, чем 01.
№ 10. По каналу связи передаются сообщения, содержащие только 4 буквы:
Е, Н, О, Т.
В любом сообщении больше всего букв О, следующая по частоте буква − Е, затем − Н. Буква Т встречается реже, чем любая другая.
Для передачи сообщений нужно использовать неравномерный двоичный код, допускающий однозначное декодирование; при этом сообщения должны быть как можно короче. Шифровальщик может использовать один из перечисленных ниже кодов. Какой код ему следует выбрать?
1) Е−0, Н−1, O−00, Т−11
2) O−1, Н−0, Е−01,Т−10
3) Е−1, Н−01, O−001, Т−000
4) О−0, Н−11, Е−101, Т−100
Пояснение.
Выберем коды, для которых выполнено условие Фано. Это коды 3 и 4.
Чтобы сообщение было как можно короче, необходимо, чтобы чем чаще встречалась буква, тем короче был ее код.
Следовательно, ответ 4, поскольку буква О - самая часто встречающаяся буква и для ее кодирования в варианте 4 используется один символ.
№ 11. Для кодирования некоторой последовательности, состоящей из букв К, Л, М, Н, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0, для буквы К - кодовое слово 110. Какова наименьшая возможная суммарная длина всех четырёх кодовых слов?
1) 7
2) 8
3) 9
4) 10
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Пояснение.
Найдём для оставшихся двух символов наиболее короткое представление, удовлетворяющее условию Фано. Кодовое слово 1 использовать нельзя, так как тогда нарушится условие Фано. Из двузначных кодовых слов можно использовать слово 10, а слова 11 и 01 использовать нельзя. При таком построении кодов для четвёртого символа невозможно подобрать двухзначное кодовое слово. Поэтому используем трёхзначное слово, а именно - 111.
Таким образом, наименьшая возможная суммарная длина всех четырёх кодовых слов будет 1 + 3 + 2 + 3 = 9.
Правильный ответ указан под номером 3.
№12. По каналу связи передаются сообщения, каждое из которых содержит 16 букв А, 8 букв Б, 4 буквы В и 4 буквы Г (других букв в сообщениях нет). Каждую букву кодируют двоичной последовательностью. При выборе кода учитывались два требования:
а) ни одно кодовое слово не является началом другого (это нужно, чтобы код допускал однозначное декодирование);
б) общая длина закодированного сообщения должна быть как можно меньше.
Какой код из приведённых ниже следует выбрать для кодирования букв А, Б, В и Г?
1) А:0, Б:10, В:110, Г:111
2) А:0, Б:10, В:01, Г:11
3) А:1, Б:01, В:011, Г:001
4) А:00, Б:01, В:10, Г:11
Пояснение.
2 и 3 не подходят, так как в них встречаются пары кодов, один из которых является началом другого.
Длина сообщений при использовании первого кода будет равна .
Длина сообщений при использовании четвёртого кода будет равна .
При использовании первого кода сообщения получаются короче, поэтому следует использовать именно его.
Чтобы пользоваться предварительным просмотром презентаций создайте себе аккаунт (учетную запись) Google и войдите в него: https://accounts.google.com
Однозначное декодирование Прямое и обратное условие Фано Учитель информатики и ИКТ МБОУ СОШ № 7 г. Оха Сахалинской области Сергиенко Татьяна Геннадьевна
Задача 1 Пусть для кодирования фразы «Доброе утро» выбран такой код: Д О Б Р Е У Т Пробел 111 000 00 1 01 0 10 11
Коды букв «сцепляются» в единую битовую строку и передаются, например, по сети: Доброе утро→ 11100000100001110101000 В пункте назначения возникает проблема – как восстановить исходное сообщение, и возможно ли это.
11100000100001110101000 Раскодировать данное сообщение можно разными способами. В том числе предположим, что оно состоит только из букв Р – 1 и У – 0. Тогда получим РРРУУУУУРУУУУРРРУРУРУУУ, т.е. бессмысленный набор букв.
Код называется однозначно декодируемым, если любое кодовое сообщение можно расшифровать единственным способом (однозначно).
Значит, код не является однозначно декодируемым.
Задача 2 Равномерные коды. Для той же фразы используем равномерный код: Д О Б Р Е У Т Пробел 111 000 001 101 011 010 100 110
Равномерные коды неэкономичны – гораздо длиннее неравномерных. Это приводит к усложнению кодирования, но при этом они раскодируются однозначно, что, естественно, облегчает задачу.
Задача 3 Чтобы сократить длину сообщения, можно попробовать применить неравномерный код, т.е. код, в котором кодовые слова, соответствующие разным символам исходного алфавита, могут иметь разную длину, от одного до нескольких символов.
Используем следующий код: 01Эта битовая цепочка декодируется однозначно. Д О Б Р Е У Т Пробел 01 00 1011 100 1010 1101 1110 1111
Первая буква - Д (код 01), т.к. ни одно другое кодовое слово не начинается с 01. Вторая буква – О (код 00). Никакое другое слово не начинается с 00. Это же свойство, которое называется условием Фано, выполняется и для кодовых слов других букв.
УСЛОВИЕ ФАНО Никакое кодовое слово не совпадает с началом другого кодового слова. Такие коды называются префиксными (раскодируются с начала сообщения) и декодируются однозначно.
Задача 4 Рассмотрим ещё один код: Он не является префиксным, т.к. код буквы Д (10) совпадает с началом кода буквы Б (1011), У(1000) и код буквы О(00) совпадает с началом кода буквы Р (001). Д О Б Р Е У Т Пробел 10 00 1011 001 0101 1000 0111 1111
Закодируем наше сообщение: ДОБРОЕ УТРО→ 10 00 1011 001 00 0101 1111 1000 0111 001 00 Начнём раскодировать с начала. Первая – Д, или У, а дальше идут вообще разные варианты: Р или Б… Т.е. надо «заглядывать» вперёд, что очень неудобно.
Попробуем раскодировать сообщение с конца – оно однозначно декодируется! Выполняется обратное условие Фано: никакое кодовое слово не совпадает с окончанием другого кодового слова.
Коды, для которых выполняется обратное условие Фано, называются постфиксными.
Сделаем вывод: Сообщение декодируется однозначно, если для используемого кода выполняется прямое или обратное условие Фано.
Условие Фано - это достаточное, но не необходимое условие однозначной декодируемости Это значит, что: - для однозначной декодируемости достаточно выполнения хотя бы одного из двух условий - прямого или обратного. - могут существовать коды, для которых не выполняется ни прямое, ни обратное условие Фано, но тем не менее обеспечивается однозначное декодирование, т.к. иначе теряется смысл выражения.
Задача 5 Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д используется неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность. Вот этот код: А – 00, Б – 01, В – 100, Г – 101, Д – 110.
Можно ли сократить для одной из букв длину кодового слова так, чтобы код по-прежнему можно было декодировать однозначно? Коды остальных букв меняться не должны. Выберите правильный вариант ответа: 1) для буквы Д -11 2) это невозможно 3) для буквы Г - 10 4) для буквы Д -10
РЕШЕНИЕ: Исходный код – префиксный. Для него выполняется условие Фано – ни один из трёхбитных кодов не начинается ни с 00 (А), ни с 01 (Б). (При этом обратное условие Фано не выполняется – код А (00) совпадает с окончанием В (100), а код Б (01) совпадает с окончанием Г (101).)
Теперь проверим ответы. Сократим Д до 11. Если полученный код нарушит прямое условие Фано, то свойство однозначного декодирования будет нарушено. Но этого не произошло, нет других кодов, начинающихся с 11. Это и есть верное решение. Проверим остальные варианты.
Вариант 2 сразу не рассматриваем – ответ у нас найден. Вариант 3 нарушает прямое условие Фано – с 10 начинается код буквы В (101). Вариант 4 – так же нарушает прямое условие Фано. Т.е. ответ однозначный, других вариантов нет.
Спасибо за внимание!
Естественно возникает вопрос: существуют ли неравномерные коды, для которых декодирование всегда однозначно? Да, существуют.
Роберт Фано сформулировал следующее достаточное условие того, что код имеет однозначное декодирование: никакое кодовое слово не является началом другого кодового слова. Если это условие выполнено, то никаких проблем с декодированием не будет.
Пусть A 1 , A 2 и A 3 - слова над некоторым алфавитом такие, что A 1 =A 2 A 3 , то есть A 1 получается из A 2 простым приписыванием к нему слова A 3 (слова A 2 или A 3 могут быть односимвольными). Назовем слово A 2 , которое является начальной частью слова A 1 , префиксом слова A 1 . Например, для слова 11101101 префиксами будут слова 1110110 , 111011 , 11101 , 1110 , 111 , 11 , 1 .
Тогда условие Фано для кодов, можно сформулировать так:
Никакое кодовое слово не является префиксом другого кодового слова .
Коды, удовлетворяющие условию Фано, называются префиксными . Итак, если код префиксный, он допускает однозначное декодирование.
Например, код, состоящий из кодовых слов {0, 10, 11} , является префиксным, и следующую кодовую последовательность 01001101110 можно разбить на кодовые слова единственным образом: 0 10 0 11 0 11 10 .
А код, состоящий из кодовых слов {0, 10, 11, 100} , префиксным не является и он не допускает однозначного декодирования. Действительно, ту же самую последовательность можно разбить на кодовые слова разными способами: 0 10 0 11 0 11 10 или 0 100 11 0 11 10 .
Важно отметить, что условие Фано является только достаточным условием однозначного декодирования для кодов, но не является необходимым условием.
Например, простой код, состоящий всего из двух кодовых слов {1, 10} , очевидно не является префиксным, но он дает однозначное декодирование любой кодовой последовательности, полученной при кодировании этим кодом. Действительно, в такой последовательности не может стоять рядом два нуля. А тогда каждый ноль со стоящей перед ней единицей заменяем на прообраз второго кодового слова, а все оставшиеся единицы - на прообраз первого слова, это и будет однозначным декодированием.
Существуют и другие, менее простые коды, обладающие тем же свойством. Например, код {01,10,011} также не является префиксным, но обладает однозначным декодированием (попробуйте доказать это самостоятельно).
Как же все-таки определить является ли код однозначно декодируемым, если для него не выполняется условие Фано? Можно использовать следующий метод.
Пусть слово A 2 является префиксом слова A 1 . Тогда A 1 =A 2 A 3 , где A 3 некоторое слово, конечная часть слова A 1 . Назовем A 3 суффиксом пары слов A 1 и A 2 , одно из которых является префиксом другого, а саму пару A 1 и A 2 назовем префиксной .
Рассмотрим в заданном коде все префиксные пары кодовых слов и построим по ним множество всех суффиксов. Далее рассмотрим все пары префиксных слов, из которых одно является кодовым, а другое – суффиксом, и для них построим суффиксы, расширяя множество суффиксов. Продолжим этот процесс до тех пор пока не перестанут появляться новые суффиксы. Код является однозначно декодируемым тогда и только тогда, когда никакой суффикс не совпадает ни с каким кодовым словом.
Например, для кода {01,10,011} множеством суффиксов будет {1,0,11} . Ни один суффикс здесь не совпадает ни с одним кодовым словом, поэтому, можно утверждать, что этот код является однозначно декодируемым.
Задача 1. Определить обладают ли свойством однозначной декодируемости следующие коды: а) {110, 11, 100, 00, 10} б) {100, 001, 101, 1101, 11011} .
Декодирование последовательностей, полученных кодами, не являющимися префиксными, требует более сложного анализа, чем для префиксных кодов. Префиксные коды иногда называют мгновенными (мгновенно декодируемыми), так как для них при чтении кодовой последовательности конец кодового слова распознается сразу по достижении конечного символа слова. В этом состоит преимущество префиксных кодов.











